More recent article on Custom XML (Jan 2010) :
- Shaving off standard XML for proprietary stuff
Previous articles :
- Backwards compatible? One more lie by omission
- Bad surprise in Microsoft Office binary documents : interoperability remains impossible
- Typical B.S. in technical articles about OOXML
- The truth about Microsoft Office compatibility
- OOXML is defective by design
Other than backwards compatibility, the expression "Custom XML" plays an important role in Microsoft ISO OOXML evangelism. It's interesting that Microsoft bloggers don't even seem to be embarassed by ridiculous expressions such as "Custom XML". Custom XML is indeed just as silly as "Office Open XML" : the reason is X in XML already means Custom. So there cannot be a meaningful sense for Custom XML...unless Custom XML is short for Custom XML applications. And from that it makes sense. But there is a problem : Custom XML is part of the ISO proposal of a document file format, whereas Custom XML applications implies the apparatus and logic related to applications, inherently tied to products, platforms and operating systems, not documents. Did Microsoft feel guilty, removed the word applications knowing it wouldn't stand a chance otherwise ? That's for anyone to guess. In this article, we are going to delve into the so-called "Custom XML", and how little useful it is in practice.
Custom XML definition, as per Microsoft
Straight from the horse behind it, Brian Jones :
Custom XML is the support for custom defined schemas. It's that support that allows you truly integrate your documents with business processes and business data. You can define your data using XML Schema syntax, and then you can use that data in your Office documents. By opening up our formats with our reference schemas, and supporting your custom defined schemas, you get true interoperability of your documents. Sorry if this is currently sounding more like a marketing pitch, but I wanted to make sure I reiterated our vision for XML support in Office documents and hopefully that will help you see the power that we see. (...) Up until now we've talked about all the parts that we in Office have defined to create our documents. You as a developer also have the ability to add your own parts though. You can take any XML file and put it inside the ZIP package.
Translation : by XML, we actually mean several completely different things, and we've put all of it in the same pot. We think storing XML-based data inside the ZIP package is an efficient way to share your confidential corporate data to the outside world and we are proud to make it easy to do so. Likewise, storing business data and the document together illustrates the grand Microsoft vision about independent layers.
Straight from the marketing people at Microsoft, here Doug Mahugh (answering Patrick Durusau during the INCITS V1 review of OOXML back in April 2007) :
DIS 29500 (OOXML) serves other purposes that are not served by ISO/IEC 26300 (ODF), especially in the area of integration options for external schemas. (By "external" I mean schemas that are not part of the spec itself -- in common usage we tend to call these "custom schemas" as opposed to the "reference schemas" in DIS 29500).
Translation : at Microsoft, we ship products to make it possible to do what you can already do without.
Straight from a top Microsoft Office brass :
Open XML allows for custom XML markup within the body of a document which is a handy way to allow users to tag their content for interoperability with other types of software such as a custom line of business system.
Translation : we dare you put foreign XML markup into an existing XML, with no agreed-upon semantics between the two languages, in order to improve the interoperability. What kind of interoperability we are talking about is left as an exercise to the reader.
Enough marketing fluff. What it really is.
First, let's get out of the way that "Custom XML" actually means "Custom" "XML" at all.
- Start Word 2007.
- Create a new document.
- Type "test".
- Save and close the document.
- Unzip it.
- Grab the part word/document.xml, you should see the following :
<w:p>
<w:r>
<w:t>test</w:t>
</w:r>
</w:p> - Now add some custom XML markup :
<w:p>
<w:r>
<w:t mytag="myvalue">test</w:t>
</w:r>
</w:p> - Put the edited part back into the ZIP file and open it in Word 2007. It opens perfectly well.
- Close it. Unzip the file again. Grab the part word/document.xml, you should see the following :
<w:p>
<w:r>
<w:t mytag="myvalue">test</w:t>
</w:r>
</w:p> - Now remove the custom attribute and instead add some other custom XML markup, this time an element :
<w:p>
<w:r>
<mytag>myvalue</mytag>
<w:t>test</w:t>
</w:r>
</w:p> - Put the edited part back into the ZIP file and open it in Word 2007. This time it brings the following error message :
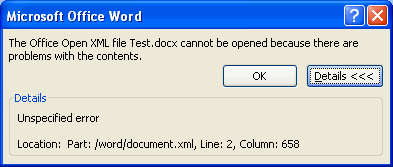
Corrupting the document by adding custom XML markup - Perhaps this is a namespace issue. Let's prefix our custom XML with w so that the fragment looks like the following :
<w:p>
<w:r>
<w:mytag>myvalue</w:mytag>
<w:t>test</w:t>
</w:r>
</w:p> - Put the edited part back into the ZIP file and open it in Word 2007, and indeed this time it opens well.
From those simple tests, we can infer the following :
- There is no such thing as strict XML schema validation in Word 2007.
- You can add a custom XML attribute with no namespace (therefore the attribute uses the element's namespace, in our case w), and Word 2007 will not complain even though the mytag attribute is not part of the OOXML reference schemas. See ECMA 376, part 4, page 199, section 2.3.2.23, the w:r element is defined as follows :
<complexType name="CT_R">
<sequence>
<group ref="EG_RPr" minOccurs="0"/>
<group ref="EG_RunInnerContent" minOccurs="0" maxOccurs="unbounded"/>
</sequence>
<attribute name="rsidRPr" type="ST_LongHexNumber"/>
<attribute name="rsidDel" type="ST_LongHexNumber"/>
<attribute name="rsidR" type="ST_LongHexNumber"/>
</complexType>
and therefore does not allow the mytag attribute to be present. - You cannot add a custom XML element unless it is prefixed by one of the namespaces declared in the header of the XML document, in our case w (xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"). Rather interesting again since w:mytag does not belong to the OOXML reference schemas, and yet Word 2007 does not complain about it.
Needless to say, this is a broken implementation of XML that neither satisfies the "strict XML" camp, nor the "loose XML" camp.
It can be summarized by the following table :
| Word 2007 | ||
| Test | Result | Strict validation |
| mytag="myvalue" | OK | NO |
| <mytag>myvalue</mytag> | FAIL | N/A |
| <w:mytag>myvalue</w:mytag> | OK | NO |
And for the other two applications, Excel 2007 and Powerpoint 2007, the results are as follows :
| Test | Word 2007 result | Excel 2007 result | Powerpoint 2007 result |
| mytag="myvalue" | OK | FAIL | FAIL |
| <mytag>myvalue</mytag> | FAIL | FAIL | FAIL |
| <w:mytag>myvalue</w:mytag> | OK | FAIL | FAIL |
Since Word 2007, Excel 2007 and Powerpoint 2007 do not handle Custom XML the same way, as the table above shows, it's very hard to trust Microsoft when they claim that Custom XML is a feature of OOXML.
Either application will see the document as a corrupt one is guaranteed to be random, Microsoft cannot possibly imply that the Custom XML they are talking about is what we take for granted when we say "Custom XML", i.e. the ability to add our own XML within the document.
Custom XML, as per ECMA 376
Since "Custom XML" does not mean "Custom" "XML", we have to rely on ECMA 376's definition of such thing. The first surprise is that there is a notion of "Custom XML markup" and a notion of "Custom XML data".
The second surprise is that the notion of "Custom XML markup" only appears in the documentation for Word documents. If we assume that this "Custom XML markup" will be used to bind the "Custom XML data" to the document at run-time, we can infer from ECMA 376 that this is only made possible for Word documents.
In other words, whatever "Custom XML" is, it is only fully implemented for Word, so it should be called "Custom XML in Word". When Microsoft marketing people are trying to sell us "Custom XML" as a feature of OOXML, it is a lie. Let's create a table of what we have just learned.
| Word 2007 | Excel 2007 | Powerpoint 2007 | |
| Custom XML data | YES | YES | YES |
| Custom XML markup | YES | NO | NO |
"Custom XML data", ECMA 376 part 4 section 8, supported in both documents, is the ability to store an independent XML stream in the ZIP package. In fact, it is not a feature of OOXML at all, it is a feature of any ZIP archive. After all, a ZIP entry in a ZIP package can be anything, including an XML stream. We can infer from that, that "Custom XML data" is in fact nothing custom : the ability to store an independent XML stream is not something we should thank Microsoft for allowing us to do so.
"Custom XML markup", ECMA 376 part 4 section 2.5, supported only in Word documents, is the ability to bind the "Custom XML data" to the document's content, at run-time. Interestingly enough, the Word team at Microsoft haven't quite managed to merge this concept and the old "smart tag" concept. That's why in the ECMA 376 specification, we end up with several flavors of "Custom XML markup", one of which is smart tags, the ability to add metadata to content (eg. stock quote).
An interesting element is "run-time". If you write the Custom XML markup that make it possible to do the said data binding, it has to be reminded that the data binding is done by an instance of Word, not a third-party application. So data binding is just a lock-in. That's the difference between standardizing on a document versus standardizing on an application!
There is no mechanism for doing such thing in Excel spreadsheets and Powerpoint presentations. In Excel spreadsheets, the XML data binding, a feature available from the user interface, is a special case of data source querying where the data source is an XML stream. The XML stream is external to the ZIP package. In other words, the "Custom XML data" in spreadsheets is useless. In Powerpoint presentations, it's even more trivial since there is no such thing as an XML data binding mechanism from the user interface.
The merit of "Custom XML data"
Something interesting to note is that Microsoft thinks that storing data inside the ZIP package independently of the document is a good thing. From a pure technical point of view, you can view this "Custom XML data" as a cache of values thanks to which the consumer is able to drill into the data without a connection to the actual data source (corporate data). But there is a major flaw. Anybody using this feature will end up storing arbitrary data in ZIP packages shared across colleagues and others inside and outside the organization. Eventually, confidential information from the corporate databases will end up there, and a PR disaster automatically follows. You don't want to use this feature.
Conclusion
"Custom XML" does not mean much, despite Microsoft ample evangelism of said feature. Technically speaking it has no merit within the enterprise space because you end up sharing corporate data. An interesting fact is that "Custom XML" is actually only implemented in Word 2007. For instance, the ECMA 376 specification provides a data binding for Word 2007 documents, exclusively. Ironically enough, the ability to store an independent XML stream as part of a ZIP package, is just a feature of the ZIP library, not Microsoft's innovation.